
The ability of making a computer learn and localize objects is one of the many applications for a technology like Computer Vision and Deep learning , most precisely called object detection. We had a task of building a custom object detector such that the model could predict food labels from food images and can be trained with minimum loss from our provided training data. The task in hand was to build a food detector for identifying different food cuisines and dishes.
Basics : What exactly is object detection ?
Object detection is a computer vision technique used to localize objects in an image by leveraging the use of object detection algorithms which uses the concepts of machine learning and deep learning . Our approach with deep learning uses Convolutional Neural Networks(CNN) to learn features and patterns necessary for detecting objects. The input data which in our case are food images serve as the input for the CNN and we feed the image matrix representation to the convolutional layers and apply a filter which can be 3×3 matrix to the input matrix through a process called convolution which yields an output matrix obtained from the dot product of the input matrix and filter matrix, it serves as the input for the next convolutional layer.The filters in the layers can help detect basic patterns such as edges , circles to complex patterns such as objects like cats, dogs etc.
The complete process :
Preparing the training data and annotation
The first and primary part is gathering the image data and labelling it by drawing the boundary boxes to help localize the position of an object. We used an annotation tool called LabelImg to annotate the data in XML files in PASCAL VOC format which is the format supported by our algorithm. Our input data is split in 80% for the training and 20% for testing and validation.
Choosing a base model and Transfer Learning

While most of the detection algorithms like R-CNN , SPP-net, Faster R-CNN consider detection as a classification problem in our case we consider it as a regression problem for which we use a Single Shot Detector(SSD) algorithm. Building a model from scratch requires a huge amount of data as input rather we can use the concept of Transfer Learning which uses the knowledge gained while solving one problem and applying it to a different but related problem. We used the SSD mobilenet architecture pre trained on the COCO dataset with 80 categories and fine tune it according to our problem. To achieve this Tensorflow provides it’s Object Detection API. The input data and XML files are required to generate TFrecords – a simple format for storing a sequence of binary records.
Training and saving the model output
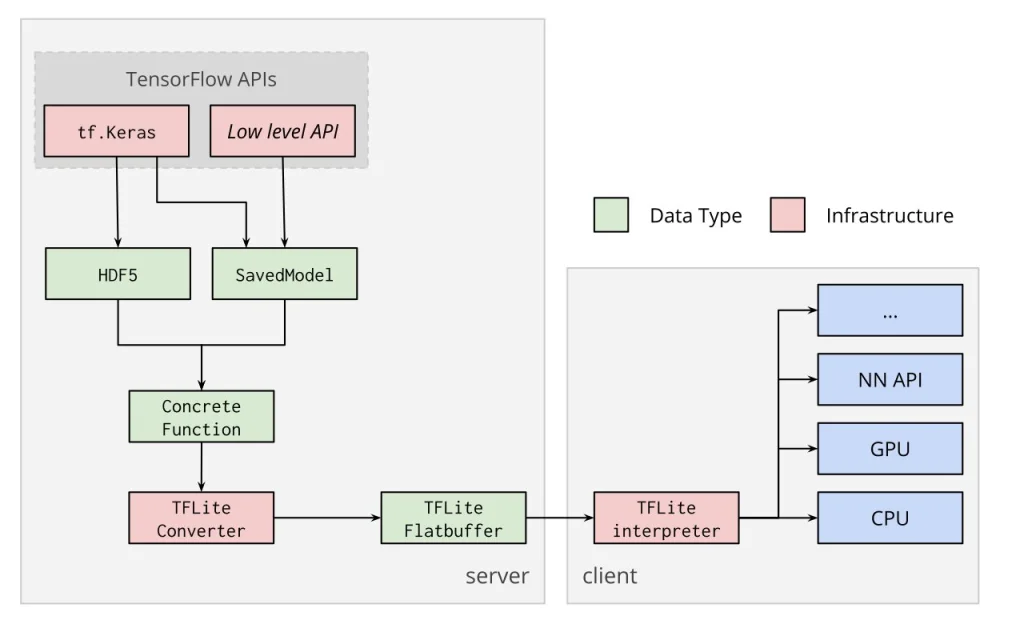
We downloaded the base model and fine-tuned the final layers of the pre trained model and retrain the network with our training data to achieve minimum loss . We can tweak the hyperparameters like steps, evaluation steps and batch size to better yield minimum loss. The the saved model generated from training which is a protobuf file (.pb) can be served for browser by converting to Tensorflow Js and on android by converting it to TFlite. Converting the saved model to TFlite requires freezing the graph and generate the frozen model which by using the TOCO Converter generates a TFlite file which can be deployed and natively used on Android.
Choosing the right platform
The fundamental requirement was choosing the right platform to execute the entire process workflow in a scalable manner. So issues we needed to address based on the initial approach included –
- Making an interface to distribute the labelling task and data collection among groups so that a workforce can be integrated to handle the task.
- Collecting the new data automatically and automate training.
- Converting the model to be used on android , browser etc.
Google Colab
The initial setup was to use the Colab platform for our processing and cloud training. Google colab provides a CPU , GPU and TPU based runtime to execute a notebook on the cloud . The input data was fetched from our Github or there’s also an option to mount the Google drive. The issues with continuing in this platform was the disk space limitations and automation . There was no way to run the notebook remotely after submission . Labelling and data submission issues still persisted as we needed continuous data to generate model for more categories and hosting the data in Github and drive didn’t allow us to version it well. Though the platform provides top of the line Tesla K-80 GPU for training with an option of specialized TPU’s.
FloydHub
FloydHub is a managed cloud platform for data scientists. It provides two ways to start the project-
FloydHub Workspace- Workspaces are fully configured development environments for deep learning on the cloud. We can create a new project and upload all the object-detection files that are stored locally to begin up using the FloydHub cloud workspace. We can run our jupyter notebook directly from workspace by selecting the tensorflow version and running mode either CPU or GPU.
FloydHub CLI- Using FloydHub command-line interface to run, monitor jobs and their results directly from the terminal. Now we can start training from cli as a job but for this we need to run this from our configured system where we have all the scripts present locally that are required in running the notebook as it uploads all files to Floydhub storage.
Issues with FloydHub-
- It requires uploading scripts with jobs every time while running a new job.
- Separating shell commands from jupyter notebook.
- Attaching the data set with every job.
- Converting saved models to tflite and other formats.
- The issue with labelling tool still persisted.
IBM cloud and Cloud Annotations
After exploring the above 2 options we discovered an online image annotation platform which allowed users to join and annotate collaboratively . The platform – Cloud Annotations is an online platform made by IBM , it gives the option to create a group and add users by inviting by mail so that they can upload data or import a dataset . The tool helps us to mark images under categories of labelled , unlabelled which allows us to track new images from the existing ones . Since Cloud annotations is a part of IBM Cloud’s range of products we have to take storage service from the services catalog where we can keep the dataset in the storage bucket and then the bucket will act as the entry point for running the training job. Cloud annotations even allow us to export the data itself after labelling to use in Google colab or other platforms .
The integration between IBM services is well orchestrated , we also use the machine learning watson instance to pipeline our entire training process . The cloud annotation platform provides its CLI to submit training jobs and download model output for web , android and iOS with the training logs and other configuration files.
After exploration IBM’s solution is best suited according to our requirements and use case . They have a robust service and a platform which is easy to use and no setup issues with the environment which was a major issue in the above others.
Challenges
- Labelling and gathering data for object detection is a major task because unlike image classification , object detection works on localizing objects from background and generating ground truth labels for these images is a big hurdle.
- Continuous flow of input data to extend the existing model’s knowledge termed as “Incremental learning” is an active research topic to be incorporated in object detection algorithms.
- To retrain the entire network again with new images data and more categories is resource intensive. Techniques of “Continual learning” will help in transfer of existing knowledge but it is also an active research topic.
Co-author : Anupam Patel
Photo by Pietro Jeng on Unsplash
