
Introduction
In the game of balancing out agility , quality and velocity for continuous business changes, automation regression keeps on growing along with your code base. A single line of code change in business logic results in creating multiple regression test cases. Also, it gets multi folded because this has to be tested on multiple devices and interfaces.
Engineering team spend lots of time in making sure our production systems are scaling and we are meeting our defined SLOs on production environment, at the same time test case regression time keeps on increasing and somehow takes a backseat until we realize that ‘Ohh it is taking half day to run all the test cases’, or sometimes may be more. This is where, your velocity of release goes for a toss. Any rerun and fixes need another iteration for same amount of time.
We went through with the same phase and our regression test case execution time increased in multifold and started touching to 12-15 hours to complete all the test cases on desktop/ simulators and multiple browsers. (How we scale on real mobile devices, is a topic for another blog post.)
We were able to reduce regression test case execution time by 75% using parallelism through cloud native approach & Making Regression test cases measurable through real time analytics for quick recovery and replay of test cases. Lets dig this out in details here.
Problem Statement
HealthKart is a power house of brands, we have a single platform on which all our brand websites (Muscleblaze.com, HKVitals.com. truebasics.com, Bgreen.com, Gritzo.com) and HealthKart.com marketplace is being run. Single change in core platform requires thousands of regression test cases to be run on different platforms and devices.
We have around 3000 cases which take full day of time for execution if any bug come in release during regression same time is take again to start over again.
Secondly, to get the failure report and rerun the failure of test cases we need to wait for the whole day to get the report because report came after all test cases execution.
Approaches for the solution
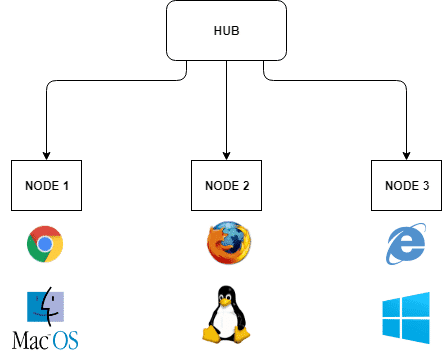
- Selenium GRID : Selenium Grid is a smart proxy server that makes it easy to run tests in parallel on multiple machines. This is done by routing commands to remote web browser instances, where one server acts as the hub. This hub routes test commands that are in JSON format to multiple registered Grid nodes.
The two major components of the Selenium Grid architecture are:
- Hub is a server that accepts the access requests from the WebDriver client, routing the JSON test commands to the remote drives on nodes. It takes instructions from the client and executes them remotely on the various nodes in parallel
- Node is a remote device that consists of a native OS and a remote WebDriver. It receives requests from the hub in the form of JSON test commands and executes them using WebDriver
Features :
- Parallel Test Execution (Local and Cloud-Based)
- Easy integration with existing selenium code .
- Seamless integration with existing code .
- Multi-Operating System Support
Cons :
- We have to maintain the nodes running through our own managed VM machines.Multiple nodes can provoke a full stop of test execution.
- Session Caches can create problem
- Challenges may emerge if multiple browsers are run on the same machine. We have to depend upon machine resources
2. Selenoid : Selenoid is a robust implementation of the Selenium hub using Docker containers to launch browsers. Fully isolated and reproducible environment.
Selenoid can launch an unhindered number of multiple browser versions concurrently.
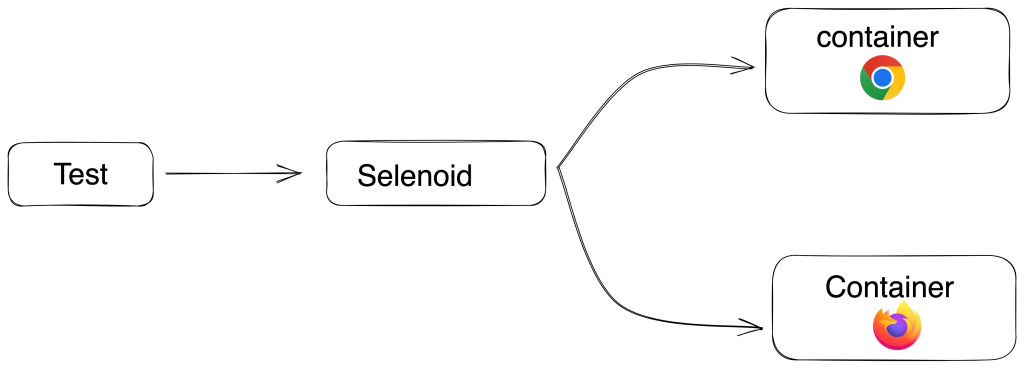
Features :
- We don’t have to maintain the nodes running
- Containers provide enough level of isolation between browser processes so
session cache is not a problem here - Real browsers are available for all version .
- Easy integration with existing selenium code .
- Docker machine run on the fly whenever test cases are running and destroyed when test case got finished .
Cons : Community for the solution is too small .
3. Browerstack : Browerstack is third party tool which run your UI test suite in minutes with parallelization on a real browser and device cloud. Test on every commit without slowing down releases, and catch bugs early.
Features :
- Real devices and browsers are available with all versions
- We can run parallel test as per our package .
- Seamless integration with existing code .
Cons : Costly implementation. Price is too high with for more parallel .
Solution we implemented
- We choose Selenoid due to ease of operability and its cloud native approach through Docker containers for achieving parallelism in distributed environment. Since we use different cloud providers in production vs dev, cloud native approach was life saver for us.
- With parallel execution of test cases through Selenoid we were able to bring the execution time to 3-4 hrs with 3000 cases . If any branch gets re-merged due to any defect found is now planned and released in a couple of hours within time.
- Integrating ELK stack for monitoring and analytics of test cases was required as test were getting executed in distributed environment and we were looking for log aggregation service which can be easily hooked in the solution architecture here. ELK stack was handy to go along. We were able to monitor and control and were able to find out the problems with test cases in real time.
Implementation of Selenoid
Selenoid is an open source project written in golang. It is an implementation of selenium grid using docker containers to launch browsers. Every time a new container is created for each test and it gets removed when the test ends. It helps in running tests in parallel mode. It also have selenoid UI which gives the clear picture of running test cases and capacity of running test case.
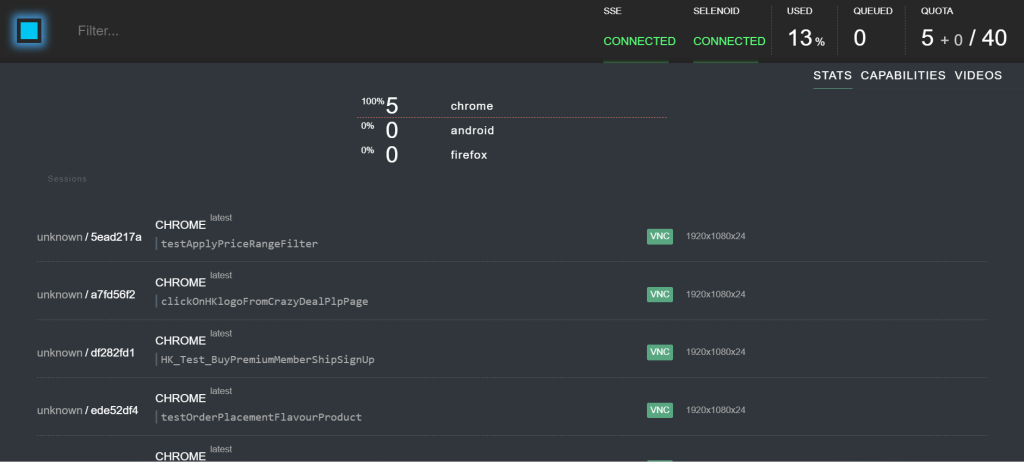
Scaling the test case capacity to run more parallel is just single configuration and also depends upon capacity of the VM where docker is launched.
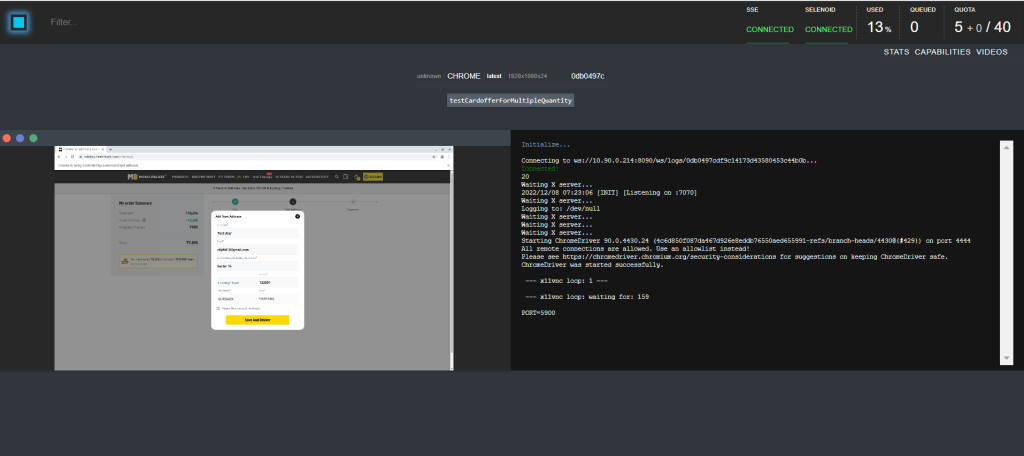
Implementation of ELK
Often referred to as Elasticsearch, the ELK stack gives you the ability to send logs in JSON format and visualise that data through kibana. With ELK implementation we can get real time data of test case failure with reason and making it actionable to rerun if required from the console.
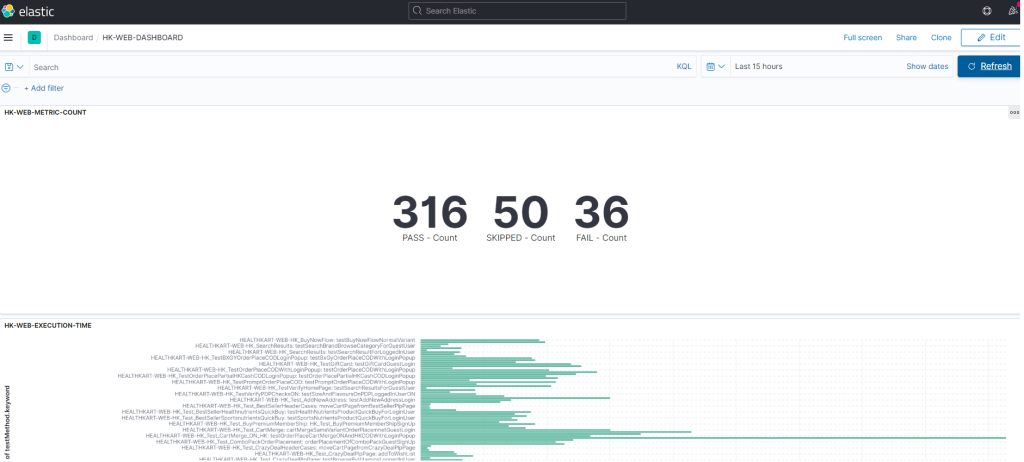
What we achieved –
- We were able to bring down our regression test case execution time to 75 % (12 hours to 3 hours). This has boosted our agility and velocity in the system at a larger scale.
- Measurable : With ELK implementation we can get real time data of test case failure with reason and making it actionable to rerun if required from the console. This again a step ahead in agility and velocity of the system.
Benefit of Implementation is cost saving
- Agility – System is more agile and adaptive to change
- Velocity : Changes can be done at faster speed
- Ease of Scalability: Highly scalable structure . If we want to increase parallel execution of test count just we need to increase the value of parallelization configuration.
- Reliable : Real time analytics dashboard gives greater control on finding out the cause and replaying/fixing it in a faster way, this makes the system more reliable and adaptive.
Value Addition (Take Away from this)
Adding a parallel execution tool to our release cycle gives a clear picture of current test cases by making videos of particular cases which make debugging easier in case of bugs. Secondly, scaling the parallel execution is too easy which makes tester life easy .
The above content is an outcome of our experience while dealing with the above problem statement. Please feel free to make comments about your own experience.
Photo by Taylor Vick on Unsplash
