
Most of you would surely agree that AWS billing mechanism is too complex and difficult to understand if you have limited experience with it. Any AWS bill where the system is internet facing and using different distributed systems internally, it is not unusual to see 15-20% bill pertaining to data transfer cost of over all AWS spend. This data cost is a result of data transfer happening between your systems available in different availability zones/ region or data being sent over the internet for serving end users.
The focus of this blog post is to share our experience with the same and navigate with different mechanisms that we used to control our data transfer cost which resulted in of approx 50% data transfer cost saving. Alright !! so let’s get started.
Let’s start by grasping the setup and pinpointing where AWS introduces charges.
- Inter-Availability Zone Data Transfer (Same Region): Data transferred between resources in different Availability Zones within the same region incur data transfer costs.
- Data Transfer Between AWS Regions: Data Transfer Between AWS Regions: When data is transferred between AWS regions (e.g., from a server in the US East region to a server in the EU West region), it incurs data transfer costs, which are typically higher than data transfer within a single region.
- Data Transfer over the Internet: Data transferred between AWS resources and the public internet may have separate data transfer costs. For example, if you have an EC2 instance that communicates with external users or services on the internet, outbound data transfer from the EC2 instance to the internet may incur costs.
The diagram presented below serves to elucidate the distinct conditions governing AWS data transfer charges. It gives you a visual snapshot of how a high-availability setup could look. Remember, this illustration is just a simplified representation, and the way your actual high-availability setup appears might have some differences. However if you deploy your application in HA your setup can appears to be a degree of resemblance.

At first glance, the costs might seem quite low when you use the AWS price calculator. However, keep in mind that these expenses can grow substantially, especially when you’re moving large amounts of data, even reaching terabytes.
Why Applications are Sending or Receiving the Data in Terabytes (TB) …
Let’s take an example of an Application, it’s might connected with MySQL, Elasticsearch and a NoSQL and you deploy your instances in the same AWS region but on a different availability zone to provide more reliability, Now here is the additional cost comes because are saving and retrieving data from different availability zone it will cost you, And when your application builds to serve for huge traffic like ecommerce, gaming or healthcare application, your data IN and OUT might go up to terabytes or more.
Now let’s figure out the how we can control the data within the platform First find out the data leakage in your application, it may be spread all over, but you can start from your application server first and enable the compressions techniques.
Enable Compression in Applications Server
By enabling compression in your Spring Boot server, you can reduce the size of data transferred over the network, leading to faster responses and improved overall performance for your application
Once you have enabled compression and set the appropriate properties, you can test it by making HTTP requests to your Spring Boot server and checking the response headers. The “Content-Encoding” header should indicate that the content has been compressed with Gzip

Customize Compression in Memcached for a Java application


Data Transfer Between Elasticsearch Nodes in different Availability Zone
Application servers which utilizes the data of ES nodes are often configured to fetch the data from ES nodes in round robin manner. This enables data transfer event between two different availability zone between Application server and elastic node.
However ES client/Application server can be configured in such a way that it will always look for ES node available in the same availability zone. In case if the server available in that zone is not available it will fall back to other nodes in different availability zone.
Below is an example code of ES java client that helps data move within a single availability zone using ElasticSearch.

Add Selective Retrieval and Compression at MySQL
Now add Compression between your application and the DB server. It will defiantly reduce some data transfer and the second thing you can implement is the Selective Retrieval If you have large datasets but only need to access a subset of the data frequently, consider partitioning or indexing your data to enable selective retrieval. This approach can save costs and improve query performance by reducing the amount of data read or transferred.
jdbc:mysql://your-database-host:3306/your-database-name?useCompression=true
Enable Client Side Configuration to Reduce Internet Data Out
After applying above changes you will see data out is reduced sufficiently. However to reduce the internet data out you need to enable the client side configuration as well, this will help client application to identify that now he has to communicate with server in said encoding format.
const headers = new Headers(req.headers)
headers.set('Content-Type', 'application/json')
headers.set('Content-Encoding', 'gzip')
return NextResponse.json(data, { status: 200, headers })`Lastly, Ensure a Comprehensive Examination of your S3 Configuration is Carried out.
Typically, AWS S3 is utilized for storing static assets like JavaScript, images, and CSS. These resources are often distributed through CDN providers for improved speed and cached delivery, as they are heavily accessed by client applications. Please make sure that these are getting accessed with compression enabled header. Also in our case we are using Cloudflare CDN on which data out bandwidth is free however data storage is S3 only. This enables us to access all our data from Cloudflare CDN, at the same time we make sure that no public access of S3 URL is available.
Realizing Cost Savings: By implementing these strategies, you will likely notice a noticeable reduction in your AWS Data Out charges. We encourage you to review our findings both before and after applying these techniques.
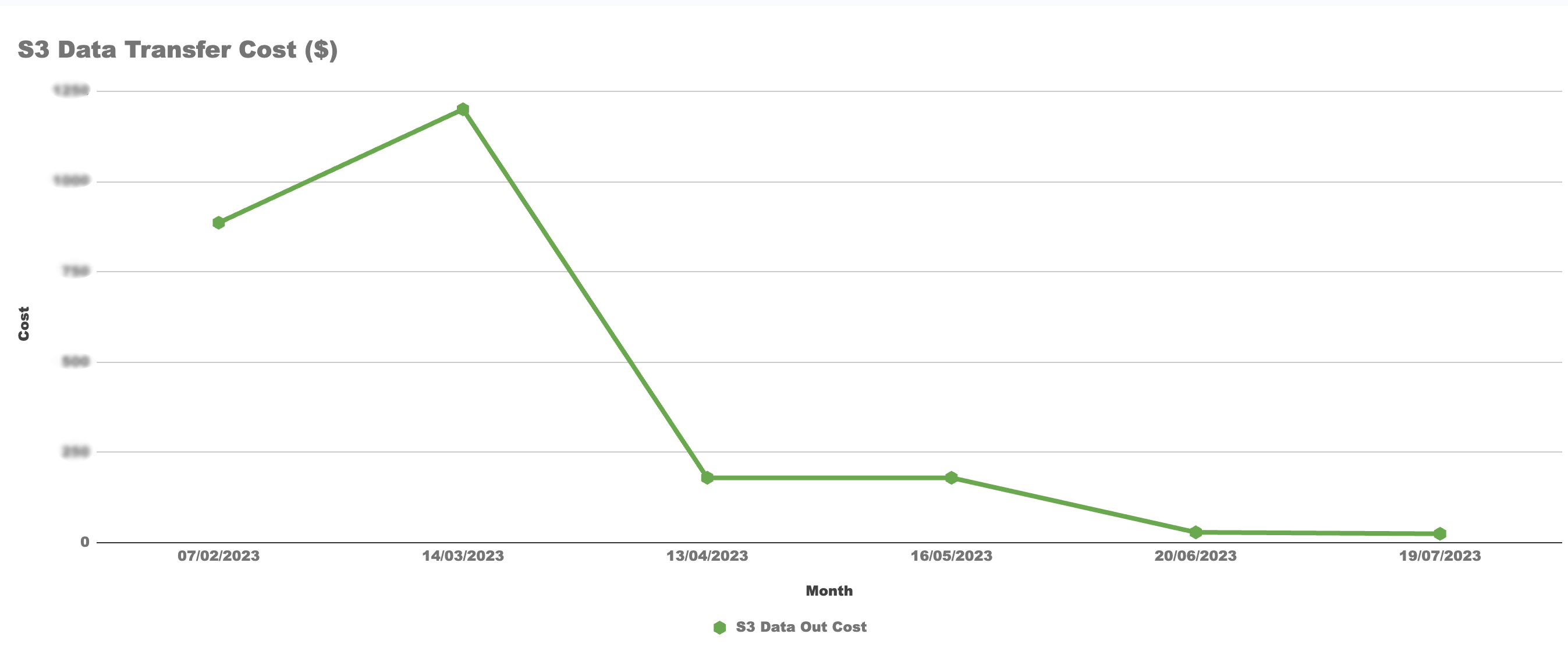

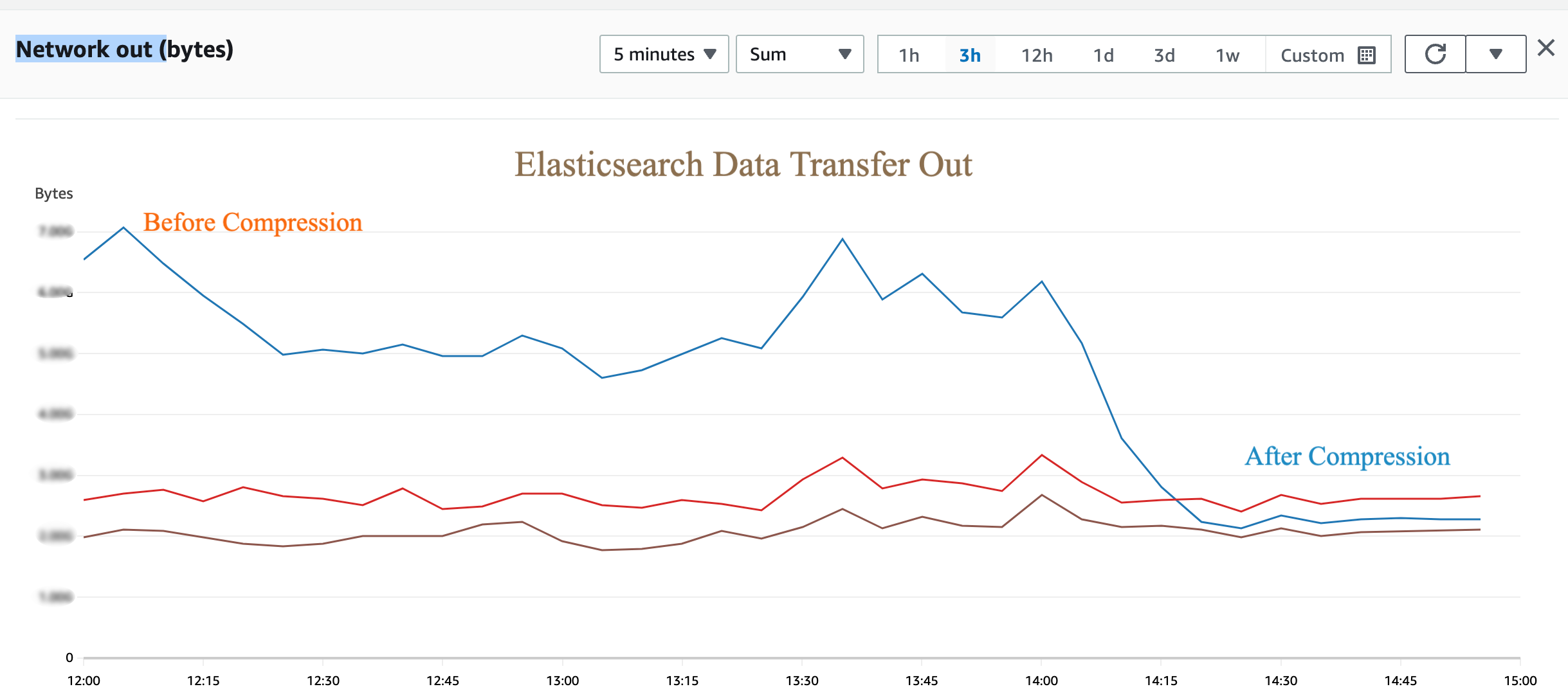



Please note that the above content is generated based on our own experience and setup. Please feel free to comment and send us the feedback in case your experience is different.
Image by Chaitawat Pawapoowadon from Pixabay
