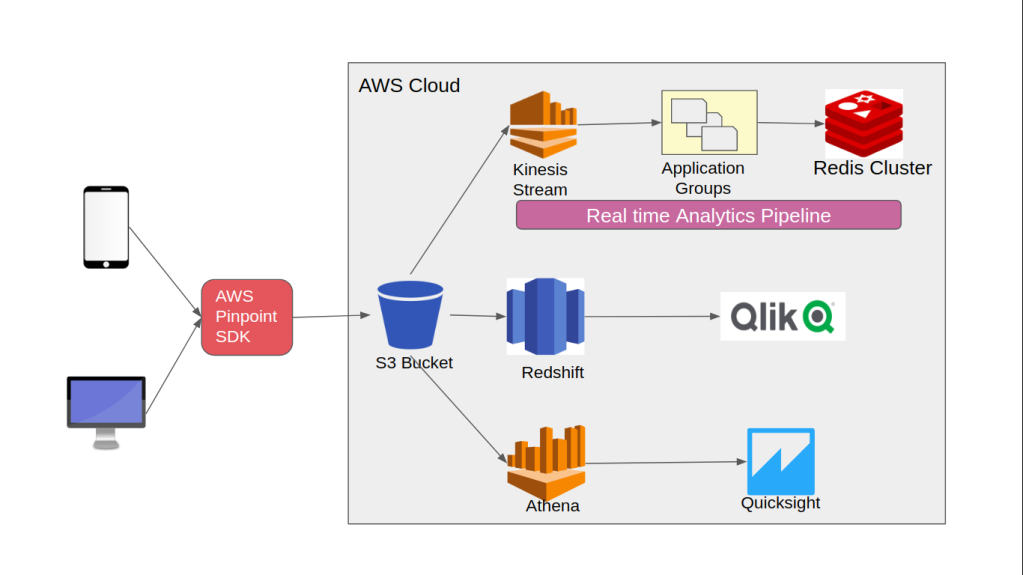
Pandemic has given exponential rise to video communication adoption to the digital platform to have better personal support service to customers. If you have a digital property, In-App video chat becomes an important aspect of the same. From a technology perspective, there are multiple options to choose from when it comes to implementation for the video chat. Lots of question will come into mind, which protocol to choose, should I use open source, should I use hosted services (CPaaS), how about the pricing and many more.
HealthKart provides nutrition services to its customer through App video chat support. Customers can initiate the Video chat service with the Nutritionist or they will get a video call in their app at the scheduled time of appointment and can have one to one consultation with the nutritionist. These kinds of implementations require few things to be considered before we actually jump to the implementation part. Let’s discuss this in detail.
Choosing right communication protocol – Technology changes rapidly and keeps on evolving every day, as a result, we keep on getting new frameworks, tools, and protocols on warp speed. What was working a couple of years back might not be relevant today. RTMP (Real-Time Messaging Protocol) which used to rule the streaming protocol earlier was replaced by HSL (HTTP Live Streaming ) from Apple and DASH (Dynamic Adaptive Streaming over HTTP) based streaming protocols. WebRTC is something new that is a game-changer as it is based on P2P and configuration support to work on TCP and UDP both. It is primarily designed for data streaming for the browser to browser support.
Looking at the WebRTC advantages we at HealthKart opt to go with WebRTC based streaming frameworks for implementing In-App Video Chat Support.
Open source Vs CPaaS (Build Vs Buy) – This might be the bit tricky call to make when it comes to whether you should build it in-house or have some hosted solution like CPaaS (Communication Platform as a Service). By any chance, if you choose to build it in house, you have to put lots of effort to find out the right server and client tools to make it work. Also need to work on its scalability and reliability part. Looking at the complexity of the service and in house capabilities and priorities we at HealthKart choose to not built this in- house instead of just looking for the hosted/CPaaS services readily available in the market.
Though this call might be contextual based on the individual needs of the organization and may vary need basis. If you need more information on what are the things one should consider, please read out our other blog post about the same here.
CPaaS – TokBox(Now Vonage) Vs Twilio Vs Others -If you decided to go ahead with hosted services, the next thing to decide would be which one to use. There are multiple CPaaS providers available in the market and one has to decide which one to use looking at the various aspects. TokBox and Twilio are leading the market on the same and we evaluated both on highlighted aspects below.
- Easy of Use – No matter which provider you choose, you have to pick their SDKs, read their developer docs and get that integrated into your app. There are lots of terminologies too that have to be understood like session Id, relay mode, routed mode etc. Tokbox and Twilio both have quite a descriptive developer guide and easy to use quick start application. Their conceptual doc is also nicely written and easy to understand. We were able to have up and running a quick start sample in web application in less than an hour. Android and iOS SDKs need integration points and configuration and required more time on that front. However, both have easy to use setup on both the front.
- Pricing – Every provider has a different pricing model and one has to understand which one will suit him best. Tokbox starts with a flat 9.99$ month with 2000 minutes subscription whereas Twilio has 0.0010 $ per minute/participants pricing model. One should do a clear calculation based on estimated user sessions and should choose the right one. Here is the quite detailed blog post for the same which will give you a good insight for right-sizing the pricing model with various CPaaS providers.
- Support – Twilio and Tokbox both have good support available in their backend. If you choose to move to an enterprise plan both will provide dedicated support available for your need. In our experience, we reached out to their support once or twice and got a fast response in support of integration.
- Feature Listing – One might need to get the support of different features too while integrating the video chat. Recording, Analytics, Intelligent Insights using AI, Text chat support are the few which might be required in some cases. Please go through with each of them to see what they have to offer.
- Extensible – See the extensible part of all the providers. Look for the ecosystem that they have and how can they support you in extending the functionality or any custom development or feature that you need on top of it. In our experience, both have limited extensibility support and do not offer much customization and features that they provide. We wanted to have incoming video call support (Similar to WhatsApp Video Calling) in our app however no out of the box solution was available in both and we had to build it on our own with the support of real-time Push Notification services on Android and iOS both. However, it was not really a deal-breaker for us as the primary requirement was to get something inbuilt in the app in agile and cost-effective way.
While considering the overall perspective we decided to use TokBox due to its super simple and Pay as you go pricing and ease of use.
The above context is based on our experience that we encounter and does not support the promotion of any of the services. Your experience with each of the services might vary. Please feel free to share your feedback and input on the same.